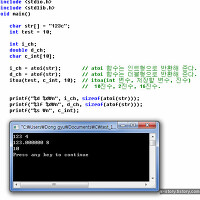
char형 int 강제 형 변환(정수의 승격.)
일단 기초부터 시작하자면.
CPU는 Word 단위로 연산을 한다. word란 CPU가 한번에 처리할 수 있는 데이터 크기를 의미한다.
우리가 흔히 말하는 32비트 시스템. window 32비트, 64비트 뭐 이런게 있는데
32bit 에서는 int를 32bit 로 표현한다. 즉 4byte.
당연히 32bit 단위로 일을 처리하는게 가장 빠르며. 때문에
char, short int 등은 int로 변환(승격) 되어진 후 연산이 되고 다시 원래대로 돌아간다.
즉, char는 int로 변환 된 후 연산하고 다시 char로 돌아간다 이야기다.
때문에 변환과 변환이 있어 사이즈가 작음에도 불구하고 더 느리다는 이야기.
사실 이 부분은 어셈블리어나 조금 더 기계적인 부분으로 들어가야 하고 이해하기 힘이드니
이정도로만 설명하겠다. 기본적으로 위의 내용이 있다는거 정도는 알아두자.
애시당초 이 글을 쓰게 된 이유는 지금부터.
구조체에서 이렇게 작은 크기의 형과 같이 묶일경우에 생기는 문제(?)이다.
unsigned char + int + char 을 묶은경우.

보이는 것과 같이 각각의 크기는 일반적으로 아는 상식으로 나오지만
총 크기를 보면 다르다는 것을 알 수 있다.

이처럼 char 또는 short가 4바이트로 같이 묶이는 것을 볼 수 있다.
이는 컴퓨터가 같은 단위로 뛰어야 연산에 편리하고 빠르기 때문으로 보인다.
double 이 있더라 하더라도 어차피 4단위로 뛰어도 같기 때문에
char와 short는 여전히 4로 잡은 상태에서 하나로 뭉쳐진다.
단, 예외(?)가 있다.

이처럼 int 자체가 전혀 없는 경우
그 다음으로 작은 단위로 바뀌어서 묶이게 된다.
위와 같은 경우 char ch[5]를 하게 되면
2byte 단위로 묶이기 때문에 총 6byte를 차치하게 되고
총 크기는 10이 되지만.
int가 있는 경우에서 ch[5]의 경우는 8이 되어 버린다.
4byte 단위로 묶이기 때문에.
어떻게 보면 공간적으로는 낭비라고 볼 수도 있지만.
속도면에서는 더 효과적이고. 요즘 같이 용량이 방대하게 커진 시대에서
사실 크기는 많이 고려하지 않을까 싶다.
선택은 자유다. 속도가 빠르다곤 하지만
일반적으로 우리 같은 학생이나 기초를 배우는 사람들에게는
이쪽이나 저쪽이나 큰 차이는 없을거다.
다만 이러한 내용을 알고는 있자는 의미에서.
변수에 담을 내용이 크지 않다면 무조건 char로 하자거나 하는
그런 말을 하지 않기를 바란다.
추가적으로. 가장 상위의 내용은 정확한 사실이지만
그 아래 구조체 관련한 내용은 위를 바탕으로 한 개인적인 추측으로
저렇게 잡이는 이유가 정확하게 맞는지는 확실하지 않다.
내가 지금 기억하고 있는 지식중 가장 근접할것 같은 이유를 적은 것이다.
그 다음으로 작은 단위로 바뀌어서 묶이게 된다.
위와 같은 경우 char ch[5]를 하게 되면
2byte 단위로 묶이기 때문에 총 6byte를 차치하게 되고
총 크기는 10이 되지만.
int가 있는 경우에서 ch[5]의 경우는 8이 되어 버린다.
4byte 단위로 묶이기 때문에.
어떻게 보면 공간적으로는 낭비라고 볼 수도 있지만.
속도면에서는 더 효과적이고. 요즘 같이 용량이 방대하게 커진 시대에서
사실 크기는 많이 고려하지 않을까 싶다.
선택은 자유다. 속도가 빠르다곤 하지만
일반적으로 우리 같은 학생이나 기초를 배우는 사람들에게는
이쪽이나 저쪽이나 큰 차이는 없을거다.
다만 이러한 내용을 알고는 있자는 의미에서.
변수에 담을 내용이 크지 않다면 무조건 char로 하자거나 하는
그런 말을 하지 않기를 바란다.
추가적으로. 가장 상위의 내용은 정확한 사실이지만
그 아래 구조체 관련한 내용은 위를 바탕으로 한 개인적인 추측으로
저렇게 잡이는 이유가 정확하게 맞는지는 확실하지 않다.
내가 지금 기억하고 있는 지식중 가장 근접할것 같은 이유를 적은 것이다.
유용한 정보가 되셨다면 아래 손가락 버튼 한번 눌러주세요 ^-^
'프로그래밍. > C언어.' 카테고리의 다른 글
| [C언어] char을 int형으로 int형을 char형으로. 간단예제. (0) | 2011.05.09 |
|---|---|
| 동적 메모리 할당 (malloc / calloc / realloc / free) (2) | 2011.04.26 |
| typedef란? typedef 사용법 (0) | 2011.03.28 |
| C언어 파일 입출력 (0) | 2011.03.28 |
| 두 개의 문서 읽어서 새로운 하나에 쓰기 (0) | 2011.03.28 |